병렬 처리
- 병렬 처리는 동시에 여러 개의 명령을 처리하여 작업의 능률을 올리는 방법으로, CPU의 핵심 기능을 가진 코어를 여러 개 만들거나 동시에 실행 가능한 명령의 개수를 늘리는 방식을 이용한다.
- 병렬 처리에서 작업을 N개로 쪼갰을 때 N을 병렬 처리의 깊이라고 한다.
- 예를 들어 병렬 처리의 깊이가 4인 경우는 작업을 네 단계로 나눈 것으로 동시에 처리할 수 있는 작업의 개수가 최대 4개이다.
- 따라서 병렬 처리의 깊이 N은 동시에 처리할 수 있는 작업의 개수를 의미한다.
- 이론적으로는 N이 커질수록 동시에 작업할 수 있는 작업의 개수가 많아져서 성능이 높아지지만, 작업을 너무 많이 나누면 각 단계마다 작업을 이동하고 새로운 작업을 불러오는데 시간이 너무 많이 걸려서 오히려 성능이 떨어진다.
- 이러한 오버헤드를 고려하여 보통은 병렬 처리의 깊이를 10~20 정도로 한다.
병렬 처리 기법
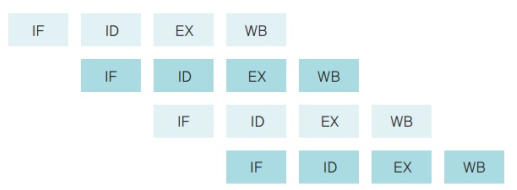
- CPU의 제어장치는 아래와 같이 명령어를 가져와 해석한 후 실행하고 결과를 저장하는 과정을 반복한다.
| 명령어 패치 (IF) | 다음에 실행할 명령어를 명령어 레지스터에 저장한다. |
| 명령어 해석 (ID) | 명령어를 해석한다. |
| 실행 (EX) | 해석한 결괄르 토대로 명령어를 실행한다. |
| 쓰기 (WB) | 실행된 결괄르 메모리에 저장한다. |
- 이러한 과정 전체를 하나의 스레드라고 하며, 스레드를 이루는 각 단계는 CPU의 클록과 연동되어 한 클록에 한 번씩 이루어진다.
- 병렬 처리 기법은 하나의 코어에서 작업을 나누어 병렬로 처리하는 파이프라인 기법과, 여러 개의 코어를 사용하여 동시에 작업을 진행하는 슈퍼스칼라 깁버으로 나뉜다.
파이프라인 기법
- CPU의 사용을 극대화하기 위해 명령을 겹쳐서 실행하는 방법으로, CPU의 사양과 연관지어 보면 하나의 코어에 여러 개의 스레드를 사용하는 것이다.

- 파이프라인 기법에서는 명령어를 여러 개의 단계로 분할한 후, 각 단계를 동시에 처리하는 하드웨어를 독립적으로 구성한다.
파이프라인의 위험
- 데이터 위험: 데이터의 의존성 때문에 발생하는 문제로, 파이프라인의 명령어 단계를 지연하여 해결한다.
- 제어 위험: 분기를 하는 if 문 또는 바로가기의 goto 문 같은 명령에서 프로그램 카운터 값이 갑자기 변화해서 발생하는 위험으로, 분기 예측이나 분기 지연 방법으로 해결한다.
- 구조 위험: 서로 다른 명령어가 같은 자원에 접근하려 할 때 발생하는 문제로, 해결하기 어렵다.
슈퍼스칼라 기법
- 파이프라인을 처리할 수 있는 코어를 여러 개 구성하여 복수의 명령어가 동시에 실행되도록 하는 방식

- 파이프라인 기법과 마찬가지로 처리되는 명령어가 상호 의존성 없이 독립적이어야 하며, 이를 위한 처리도 컴파일러에서 이루어지도록 조정해야 한다.
- 오늘날의 CPU는 대부분 슈퍼스칼라 기법을 사용하고 있다.
VLIW 기법
- CPU가 병렬 처리를 지원하지 않을 경우 소프트웨어적으로 병렬 처리하는 방법으로, 위의 방법들에 비해 동시에 처리하는 명령어의 개수가 적다.
- VLIW 기법은 동시에 수행할 수 있는 명령어들을 컴파일러가 추출하고 하나의 명령어로 압축하여 실행한다.
- 위의 병렬 처리 기법들은 명령어 실행 시 병렬 처리가 이루어지지만, VLIW 기법은 컴파일 시 병렬 처리가 이루어진다.
'Computer Science > Operating System' 카테고리의 다른 글
| 프로세스 제어 블록과 문맥교환 (0) | 2022.03.15 |
|---|---|
| 프로세스와 스레드 (0) | 2022.03.15 |
| 컴퓨터 성능 향상 기술 (0) | 2022.03.14 |
| 컴퓨터 구조 (0) | 2022.03.14 |
| 운영체제 개요 (0) | 2022.03.14 |