RDB vs NoSQL
RDB
관계형 데이터베이스는 엄격한 스키마를 요구하는 테이블 기반 데이터 구조를 갖습니다.
[장점]
- 데이터의 형태와 크기를 미리 정하고 테이블 단위로 구분하여 데이터를 저장할 수 있다.
- 트랜잭션을 통해 ACID를 보증하여 안정적인 데이터 관리가 가능하다.
- 조인을 포함해 복잡한 조건을 포함하는 데이터 검색이 가능하다.
- 엄격한 스키마로 인해 데이터 중복이 없기 때문에 데이터 update가 많을 때 유리하다.
[문제점]
웹이 기하급수적으로 성작하면서, SNS를 통해 작성되는 자유로운 형태의 텍스트와 로그 기록 같은 다양한 유형의 비정형 데이터가 빠른 속도로 대량 생산되고 있습니다. 관계형 데이터베이스는 이러한 대량의 비정형 데이터를 저장하고 처리하기에 맞지 않습니다.
또한 여러 컴퓨터가 연결되어 하나의 시스템을 구성하는 클러스터 환경에서는 확장성이 무엇보다 중요한데, 단일 컴퓨터 환경에서 주로 사용되는 관계형 데이터베이스는 클러스터 환경에서 효율적으로 동작하도록 설계되지 않았다는 문제점도 있습니다.
웹에서 대량의 비정형 데이터의 저장과 처리를 위해 관계형 데이터베이스를 대신할 새로운 대안으로 제시된 것이 NoSQL
NoSQL
빠른 속도로 생성되는 대량의 비정형 데이터를 저장하고 처리하기 위해 ACID를 위한 트랜잭션 기능을 제공하지 않는 대신, 저렴한 비용으로 여러 대의 컴퓨터에 데이터를 분산/저장/처리하는 것이 가능한 데이터베이스입니다.
[특징]
- 스키마 없이 동작하기 때문에 데이터 구조를 미리 정의할 필요가 없고, 수시로 그 구조를 바꿀 수 있어 비정형 데이터를 저장하기에 적합하다.
- But 데이터 중복으로 인해 데이터 update 시 모든 컬렉션에서 수정이 필요하기 때문에 update가 적고 조회가 많을 때 유리하다.
- 따라서 저장될 데이터의 형태와 처리 목적에 따라 RDMBS와 NoSQL 중 적합한 데이터베이스를 선택해야 한다.
정리
| RDBMS | NoSQL | |
| 처리 데이터 | 정형 데이터 | 정형 데이터, 비정형 데이터, 반정형 데이터 |
| 대용량 데이터 | 대용량 처리 시 성능 저하 | 대용량 데이터 처리 지원 |
| 스키마 | 미리 정해진 스키마 존재 | 스키마가 없거나 변경이 자유로움 |
| 트랜잭션 | 트랜잭션을 통해 일관성 유지를 보장함 | 트랜잭션을 지원하지 않아 일관성 유지를 보장하기 어려움 |
| 검색 기능 | 조인 등의 복잡한 검색 기능 제공 | 단순한 데이터 검색 기능 제공 |
| 확장성 | 클러스터 환경에 적합하지 않음 | 클러스터 환경에 적합 |
| 라이선스 | 고가의 라이선스 비용 | 오픈 소스 |
| 종류 | Oracle, MySQL, MS SQL 서버 등 | 카산드라, MongoDB, HBase 등 |
| 언제 사용?? | 데이터 구조가 변경될 여지가 없이 명확한 경우 | 정확한 데이터 구조가 정해지지 않은 경우, 데이터 양이 매우 많은 경우 (수평적 확장 가능) |
NoSQL 종류
NoSQL은 어떤 데이터 모델로 데이터를 저장하느냐에 따라 크게 네 가지로 분류할 수 있습니다.

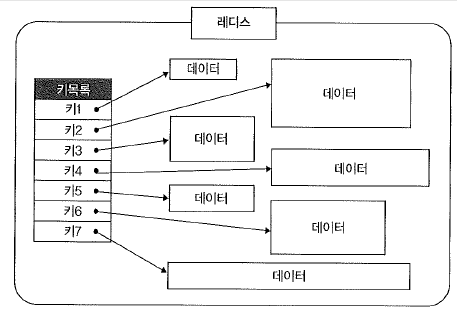
Key-Value
[특징]
- NoSQL의 가장 단순한 형태로, 키와 값의 쌍으로 데이터가 저장됩니다.
- 이미지와 동영상은 물론 어떠한 형태의 값도 저장할 수 있고 질의 처리 속도가 빠르다는 장점!
- 키를 통해 특정 값을 지정하기 때문에 키를 이용해 값 전체를 검색할 수는 있지만, 값의 일부를 검색하거나 값의 내용을 이용한 질의에는 별도의 처리가 필요합니다.
[예시] 아마존의 DynamoDB, 트위터 등에서 사용되는 Redis
Document
[특징]
- 키-값 데이터 모델이 확장된 형태로, 키와 문서의 쌍으로 데이터를 저장합니다.
- 키-값 모델과 달리 트리 형태로 계층적 구조가 존재하는 JSON, XML 같은 반정형 형태의 문서로 데이터를 저장합니다.
- 키를 통해 문서 전체를 검색하는 것도 가능하지만 XQuery와 같은 특별한 문서 대상 질의 언어를 이용하면 문서 내의 일부를 검색하거나 질의에 활용할 수 있습니다.
[예시] MongoDB, CouchDB

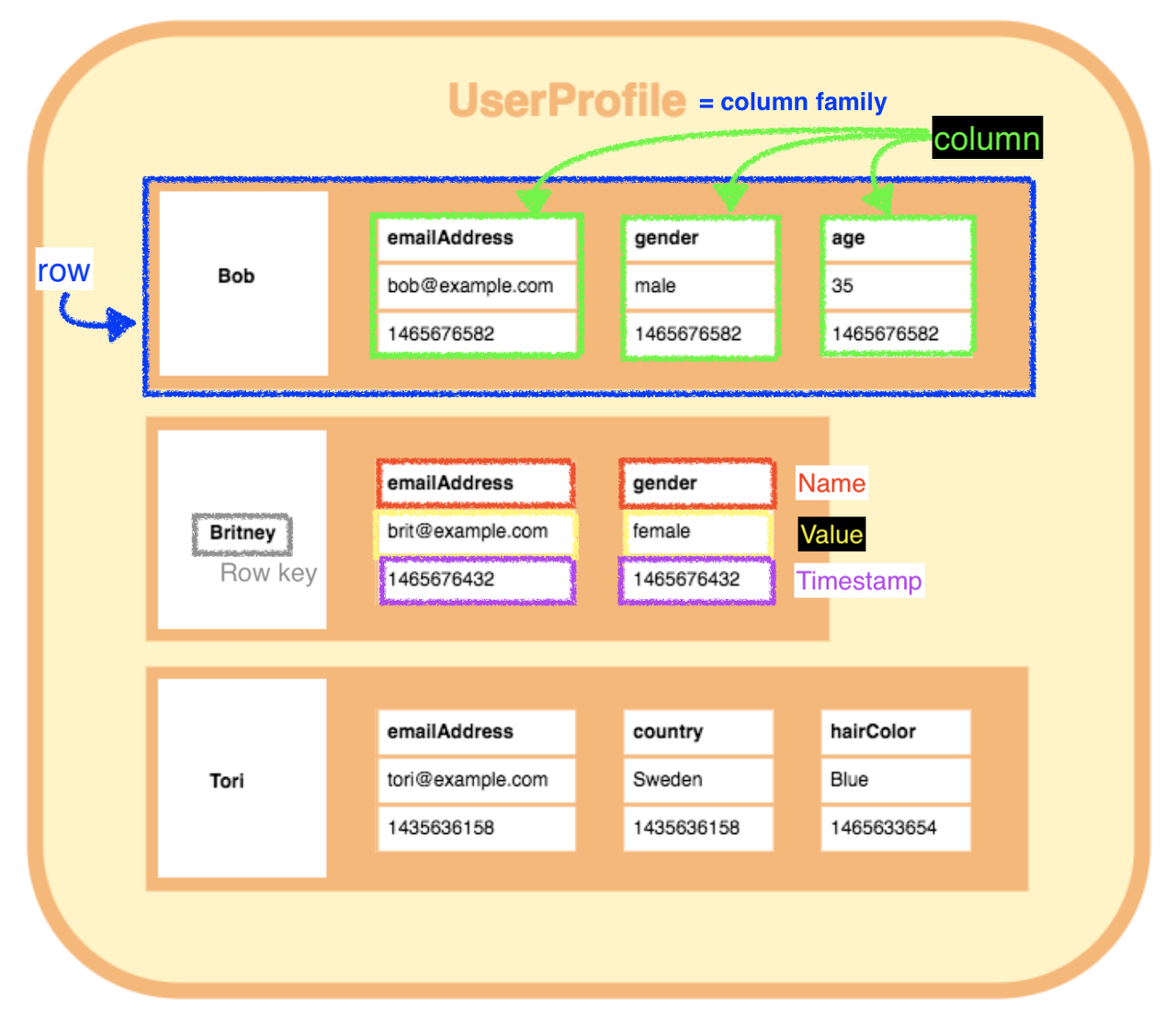
Column
[특징]
- 컬럼 패밀리와 키의 쌍으로 데이터를 저장합니다.
- 컬럼 패밀리는 테이블에서 한 개의 행을 구성하는 속성들의 모임으로, 각 행을 구분하는 키로 각 컬럼 패밀리를 식별
- 다양한 형태의 데이터를 값으로 저장할 수 있고, 행마다 컬럼의 구성을 다르게 할 수 있습니다.
[예시] 구글의 BigTable, HBase, 카산드라
Graph
[특징]
- 그래프 데이터 모델은 데이터는 물론 데이터 간의 관계를 표현하는데 적합합니다.
- 노드에 데이터를 저장하고 간선으로 데이터 간의 관계를 표현하는 그래프의 형태로, 질의는 그래프 순회 과정을 통해 처리합니다.
- 다른 NoSQL 데이터 모델과 달리 트랜잭션을 통해 ACID를 지원하며 클러스터 환경에는 적합하지 않은 대신, 연관 데이터를 추천해주거나 소셜 네트워크에서 친구 찾기 질의를 효과적으로 수행하는 데 적합합니다.
[예시] Neo4J, OrientDB

'Computer Science > Database' 카테고리의 다른 글
| Join 알고리즘 (0) | 2022.07.20 |
|---|---|
| 트랜잭션과 ACID (0) | 2022.02.22 |
| `이상현상과 정규화 (0) | 2022.02.22 |
| JOIN의 종류 (0) | 2022.02.19 |
| `서브쿼리와 뷰 (0) | 2022.02.19 |