Spring Data
- 스프링 데이터 프로젝트는 여러 개의 하위 프로젝트로 구성되는 다소 규모가 큰 프로젝트로, 대부분의 하위 프로젝트는 다양한 데이터베이스 유형을 사용한 데이터 퍼시스턴스에 초점을 둔다.
- 스프링 데이터에서는 repository 인터페이스를 기반으로 이 인터페이스를 구현하는 repository를 자동 생성해 준다.
| 스프링 데이터 JPA | 관계형 데이터베이스 JPA 퍼시스턴스 |
| 스프링 데이터 MongoDB | 몽고 문서형 데이터베이스의 퍼시스턴스 |
| 스프링 데이터 Neo4 | Neo4j 그래프 데이터베이스의 퍼시스턴스 |
| 스프링 데이터 레디스 | 레디스 키-값 스토어의 퍼시스턴스 |
| 스프링 데이터 카산드라 | 카산드라 데이터베이스의 퍼시스턴스 |
Spring Data JPA
- 스프링 데이터 JPA는 스프링 프레임워크에서 JPA를 편리하게 사용할 수 있도록 지원하는 프로젝트로, 데이터 접근 계층을 개발할 때 반복되는 CRUD 문제를 해결한다.
- CRUD 처리를 위한 공통 인터페이스(JpaRepository)를 제공하므로, 리포지토리를 개발할 때 인터페이스만 작성하면 실행 시점에 스프링 데이터 JPA가 구현 객체를 동적으로 생성해서 주입해준다.
- 스프링 데이터 JPA를 사용하는 방법은 JpaRepository 인터페이스를 상속받고, 제네릭에 엔티티 클래스와 엔티티 클래스가 사용하는 식별자 타입을 지정한다.
public interface MemberRepository extends JpaRepository<Member, Long> {
}
공통 인터페이스 기능
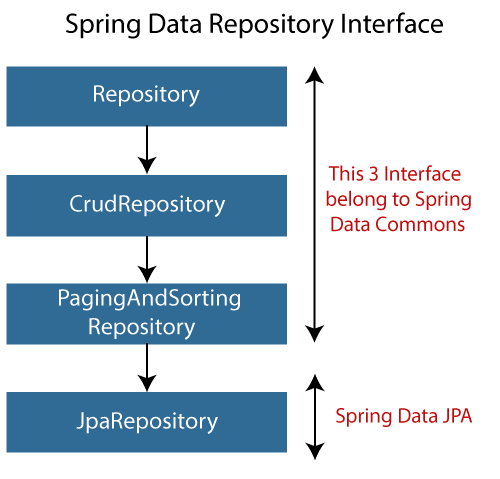
- Repository, CrudRepository, PagingAndSortingRepository는 스프링 데이터 프로젝트가 공통으로 사용하는 인터페이스이며, 스프링 데이터 JPA가 제공하는 JpaRepository 인터페이스는 추가로 JPA에 특화된 기능을 제공한다.
- JpaRepository 인터페이스를 상속받으면 사용할 수 있는 주요 메서드는 다음과 같다.
| save(S) | 새로운 엔티티는 저장하고 이미 있는 엔티티는 수정한다. (엔티티에 식별자 값이 없으면 새로운 엔티티로 판단해서 em.persist()를 호출하고, 식별자 값이 있으면 em.merge()를 호출한다.) |
| delete(T) | 엔티티 하나를 삭제한다. (내부에서 em.remove() 호출) |
| findOne(ID) | 엔티티 하나를 조회한다. (내부에서 em.find() 호출) |
| getOne(ID) | 엔티티를 프록시로 조회한다. (내부에서 em.getReference() 호출) |
| findAll() | 모든 엔티티를 조회한다. 정렬이나 페이징 조건을 파라미터로 제공할 수 있다. |
쿼리 메소드 기능
메소드 이름으로 쿼리 생성
- 인터페이스에 메서드만 선언하면 해당 메서드 이름으로 적절한 JPQL 쿼리를 생성해서 실행한다.
- 대신 메서드의 이름은 아래 규칙에 맞게 지어야 한다.
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods.query-creation
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
@Query
- @Query 어노테이션을 사용해서 리포지토리 메서드에 쿼리를 직접 정의하는 방법
- 실행할 메서드에 정적 쿼리를 직접 작성하며, 애플리케이션 실행 시점에 문법 오류를 발견할 수 있다는 장점이 있다.
// @Query
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);
반환 타입
- 스프링 데이터 JPA는 결과가 한 건 이상이면 컬렉션 인터페이스를 사용하고, 단건이면 반환 타입을 지정한다.
- 만약 조회 결과가 없으면 컬렉션은 빈 컬렉션을 반환하고, 단건은 null을 반환한다.
- 만약 단건을 기대하고 반환 타입을 지정했는데 결과가 2건 이상 조회되면 예외가 발생하지만, 스프링 데이터 JPA는 예외가 발생하면 예외를 무시하고 대신 null을 반환한다.
List<Member> findListByUsername(String name); //컬렉션
Member findMemberByUsername(String name); //단건
Optional<Member> findOptionalByUsername(String name); //단건 Optional
페이징과 정렬
- 스프링 데이터 JPA는 쿼리 메소드에 페이징과 정렬 기능을 사용할 수 있도록 특별한 파라미터를 제공한다.
- Sort - 정렬 기능
- Pageable - 페이징 기능 (내부에 Sort 포함)
- 파라미터에 Pageable을 사용하면 반환 타입으로 List나 Page를 사용할 수 있으며, Page를 사용하면 스프링 데이터 JPA는 페이징 기능을 제공하기 위해 검색된 전체 데이터 건수를 조회하는 count 쿼리를 추가로 호출한다.
// 페이징
Page<Member> findByAge(int age, Pageable pageable);
// count 쿼리 분리 가능
@Query(value = "select m from Member m",
countQuery = "select count(m.username) from Member m")
Page<Member> findMemberAllCountBy(Pageable pageable);- 파라미터로 받은 Pageable은 인터페이스로, 실제 사용할 때는 인터페이스를 구현한 PageRequest 객체를 사용한다.
- PageRequest 생성자의 첫 번째 파라미터에는 현재 페이지를, 두 번재 파라미터에는 조회할 데이터 수를 입력한다.
- 추가로 정렬 정보도 사용 가능
'Spring > JPA' 카테고리의 다른 글
| 영속성 컨텍스트와 연속성 관리 (0) | 2022.03.05 |
|---|---|
| N+1 문제와 해결 방법 (0) | 2022.03.05 |
| JPA와 ORM (0) | 2022.02.23 |
| JPQL과 페치 조인 (0) | 2022.02.23 |
| QueryDSL (0) | 2022.02.04 |