실행 계획
- 실행 계획이란 SQL 문으로 요청한 데이터를 어떻게 불러올 것인지에 관한 계획, 즉 경로를 의미한다.
- 실행 계획을 확인하는 키워드로는 EXPLAIN, DESCRIBE, DESC가 있으며, 3가지 중 어떤 키워드를 사용해도 실행 계획의 결과는 같다.
EXPLAIN SQL 문;
DESCRIBE SQL 문;
DESC SQL 문;
MySQL
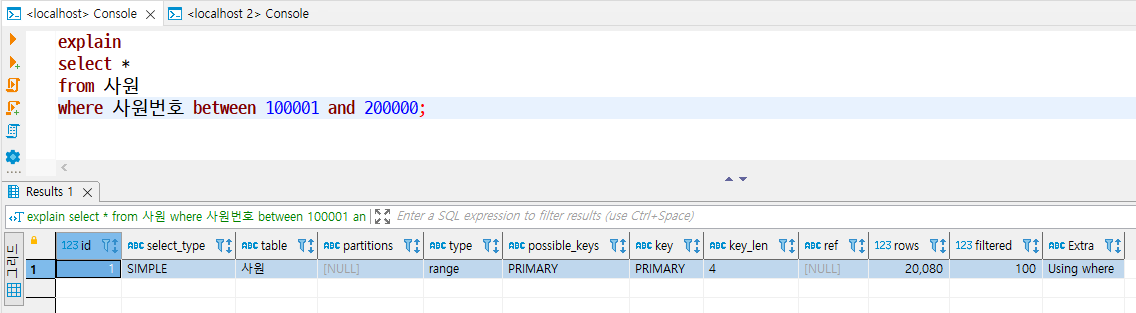
- SQL 문 앞에 EXPLAIN 키워드를 입력하고 실행하면 옵티마이저가 만든 실행 계획이 출력된다.
- MariaDB에 비해 partitions, filtered 열이 추가되면서 더 많은 정보를 보여준다.
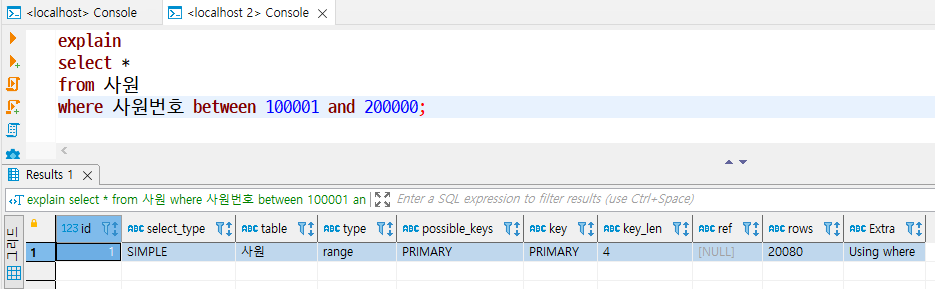
MariaDB
실행 계획 항목 분석
1. id
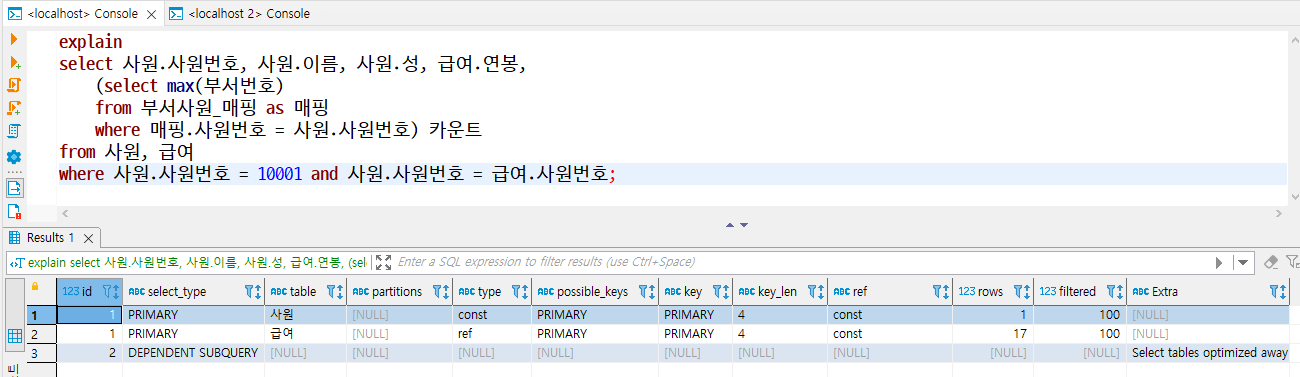
- SQL 문이 수행되는 차례를 ID로 표기한 것으로, 조인할 때는 똑같은 ID가 표시된다.
- ID의 숫자가 작을수록 먼저 수행된 것이고 ID가 같은 값이라면 두 개 테이블의 조인이 이루어졌다는 것을 알 수 있다.
- 아래 예제를 보면 첫 번째 행과 두 번재 행의 ID 값이 1이므로 조인이 발생했고, 세 번째 행의 ID 값이 2이므로 조인이 이루어진 뒤에 세 번째 행이 수행된 것이라고 생각할 수 있다.
2. select_type
- SQL 문을 구성하는 SELECT 문의 유형을 출력하는 항목
- SELECT 문이 단순히 FROM 절에 위치한 것인지, 서브쿼리인지, UNION 절로 묶인 SELECT 문인지 등의 정보를 제공한다.
SIMPLE
- UNION이나 내부 쿼리가 없는 SELECT 문이라는 걸 의미하며, 단순한 SELECT 구문으로만 작성된 경우를 가리킨다.
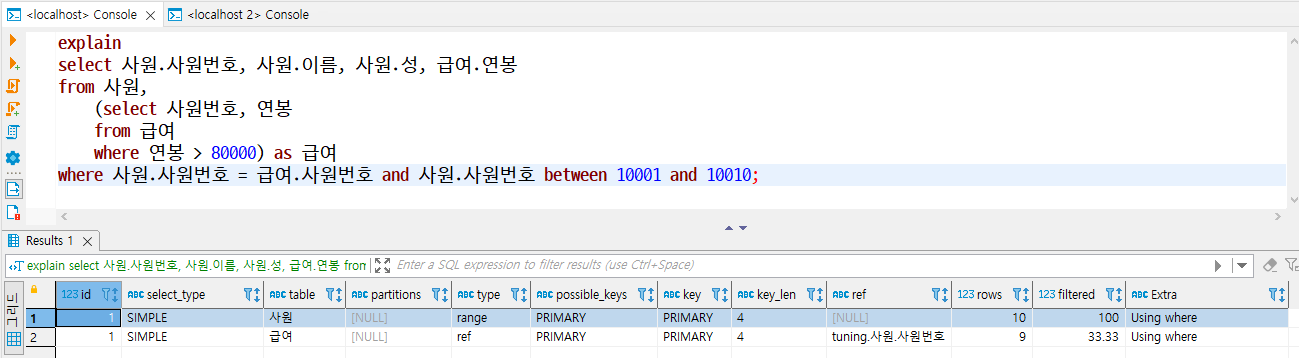
PRIMARY
- 서브쿼리가 포함된 SQL 문이 있을 때 첫 번째 SELECT 문에 해당하는 구문에 표시되는 유형
- 서브쿼리르 감싸는 외부 쿼리이거나, UNION이 포함된 SQL 문에서 첫 번째로 SELECT 키워드가 작성된 구문에 표시된다.

SUBQUERY
- 독립적으로 수행되는 서브쿼리를 의미하며, SELECT 절의 스칼라 서브쿼리와 WHERE 절의 중첩 서브쿼리일 경우 해당된다.

DERIVED
- FROM 절에 작성된 서브쿼리라는 의미로, FROM 절의 별도 임시 테이블인 인라인 뷰를 말한다.

UNION
- UNION 및 UNION ALL 구문으로 합쳐진 SELECT 문에서 첫 번째 SELECT 구문을 제외한 이후의 SELECT 구문에 해당한다는 것을 나타낸다.
- UNION 구문의 첫 번째 SELECT 절은 PRIMARY 유형으로 출력된다.

UNION RESULT
- UNION ALL이 아닌 UNION 구문으로 SELECT 절을 결합했을 때 출력된다.
- UNION은 출력 결과에 중복이 없는 유일한 속성을 가지므로 각 SELECT 절에서 데이터를 가져와 정렬하여 중복 체크하는 과정을 거친다.
- 따라서 UNION RESULT는 별도의 메모리 또는 디스크에 임시 테이블을 만들어 중복을 제거하겠다는 의미로 해석할 수 있다.
- UNION 구문으로 결합되기 전의 각 SELECT 문이 결과가 중복되지 않음이 보장될 때는 UNION ALL 구문으로 변경하는 것이 좋다.

DEPENDENT SUBQUERY
- UNOIN 또는 UNION ALL을 사용하는 서브쿼리가 메인 테이블의 영향을 받는 경우로, UNION으로 연결된 단위 쿼리들 중에서 처음으로 작성한 단위 쿼리에 해당되는 경우를 말한다.
- 즉, UNION으로 연결되는 첫 번째 단위 쿼리가 독립적으로 수행되지 못하고 메인 테이블로부터 값을 하나씩 공급받는 구조이므로 성능적으로 불리하여 튜닝 대상이 된다.

DEPENDENT UNION
- UNOIN 또는 UNION ALL을 사용하는 서브쿼리가 메인 테이블의 영향을 받는 경우로, UNION으로 연결된 단위 쿼리 중 첫 번째 단위 쿼리를 제외하고 두 번째 단위 쿼리에 해당하되는 경우를 말한다.
- 즉, UNION으로 연결되는 두 번째 이후의 단위 쿼리가 독립적으로 수행되지 못하고 메인 테이블로부터 값을 하나씩 공급받는 구조이므로 성능적으로 불리하여 튜닝 대상이 된다.
UNCACHEABLE SUBQUERY
- 메모리에 상주하여 재활용되어야 할 서브쿼리가 재사용되지 못할 때 출력되는 유형
- 해당 서브 쿼리 안에 사용자 정의 함수나 사용자 변수가 포함되거나, RAND(), UUID() 함수 등을 사용하여 매번 조회 시마다 결과가 달라지는 경우에 해당된다.
- 만약 자주 호출되는 SQL 문이라면 메모리에 서브쿼리 결과가 상주할 수 있도록 변경하는 방향으로 SQL 튜닝을 검토해 볼 수 있다.
MATERIALIZED
- IN 절 구문에 연결된 서브쿼리가 임시 테이블을 생성한 뒤, 조인이나 가공 작업을 수행할 때 출력되는 유형
- 즉, IN 절의 서브쿼리를 임시 테이블로 만들어서 조인 작업을 수행하는 것

3. table
- 실행 계획 정보에서 테이블명이나 테이블 별칭을 출력하며, 서브쿼리나 임시 테이블을 만들어서 별도의 작업을 수행할 때는 <subquery#>이나 <derived#>으로 출력된다.

4. partitions
- 실행 계획의 부가 정보로, 데이터가 저장되는 논리적인 영역을 표시하는 항목
- 사전에 정의한 전체 파티션 중 특정 파티션에 선택적으로 접근하는 것이 SQL 성능 측면에서 유리하다.
- 만약 너무 많은 영역의 파티션에 접근하는 것으로 출력된다면 파티션 정의를 튜닝해야 한다.
5. type
- 테이블의 데이터를 어떻게 찾을지에 관한 정보를 제공하는 항목으로, 테이블의 처음부터 끝까지 전부 확인할지 아니면 인덱스를 통해 바로 데이터를 찾아갈지 등을 해석할 수 있다.
system
- 테이블에 데이터가 없거나 한 개만 있는 경우로, 성능상 최상의 type이라고 할 수 있다.

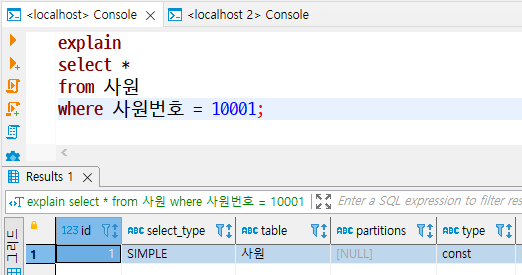
const
- 조회되는 데이터가 단 1건일 때 출력되는 유형으로, 성능상 매우 유리한 방식
- 고유 인덱스나 기본 키를 사용하여 단 1건의 데이터에만 접근하면 되므로, 속도나 리소스 사용 측면에서 좋다.
eq_ref
- 조인이 수행될 때 드리븐 테이블의 데이터에 접근하며 고유 인덱스 또는 기본 키로 단 1건의 데이터를 조회하는 방식
- 드라이빙 테이블과의 조인 키가 드리븐 테이블에 유일하므로 조인이 수행될 때 성능상 가장 유리한 경우라고 할 수 있다.
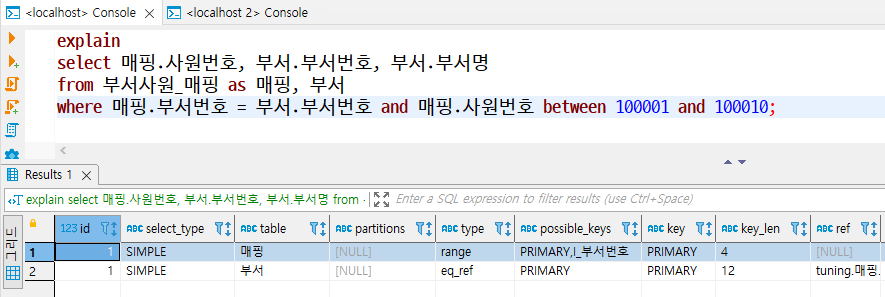
ref
- eq_ref와 유사하게 조인을 수행할 때 드리븐 테이블의 데이터 접근 범위가 2개 이상일 경우를 의미한다.
- 드라이빙 테이블과 드리븐 테이블을 조인하면 일대다 관계가 되므로, 드라이빙 테이블의 1개 값이 드리븐 테이블에서는 2개 이상의 데이터로 존재한다.
- 이때 기본 키나 고유 인덱스를 활용하면 2개 이상의 데이터가 검색되거나, 유일성이 없는 비고유 인덱스를 사용하게 된다.
- 드리븐 테이블의 데이터양이 많지 않을 때는 성능 저하를 크게 우려하지 않아도 되지만, 데이터양이 많다면 접근해야 할 데이터 범위가 넓어져 성능 저하의 원인이 되는지 확인해야 한다.
- 또한, =, <, > 등의 연산자를 사용해 인덱스로 생성된 열을 비교할 때도 ref가 출력된다.
ref_or_null
- ref 유형과 유사하지만 IS NULL 구문에 대해 인덱스를 활용하도록 최적화된 방식
- MySQL과 MariaDB는 NULL에 대해서도 인덱스를 활용하여 검색할 수 있으며, 이때 NULL은 가장 앞쪽에 정렬된다.
- 테이블에서 검색할 NULL 데이터양이 적다면 ref_or_null 방식을 활용하는 것이 효율적이지만, 검색할 NULL 데이터양이 많다면 SQL 튜닝 대상이 된다.
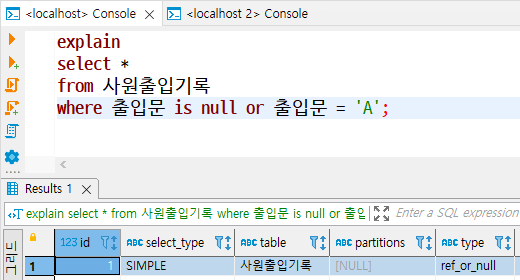
range
- 테이블 내의 연속된 데이터 범위를 조회하는 유형으로, 범위 스캔을 수행하는 방식
- 주어진 데이터 범위 내에서 행 단위로 스캔하지만, 스캔할 범위가 넓으면 성능 저하의 요인이 될 수 있으므로 SQL 튜닝 대상이 된다.

fulltext
- 텍스트 검색을 빠르게 처리하기 위해 전문 인덱스를 사용하여 데이터에 접근하는 방식
index_merge
- 결합된 인덱스들이 동시에 사용되는 유형으로, 특정 테이블에 생성된 두 개 이상의 인덱스가 병합되어 동시에 적용된다. (전문 인덱스는 제외)

index
- 인덱스 풀 스캔을 의미하며, 물리적인 인덱스 블록을 처음부터 끝까지 훑는 방식
- 데이터를 스캔하는 대상이 인덱스라는 점이 다를 뿐 all 유형과 유사하다.
- 인덱스는 보통 테이블보다 크기가 작으므로 테이블 풀 스캔 방식보다는 빠를 가능성이 크다.

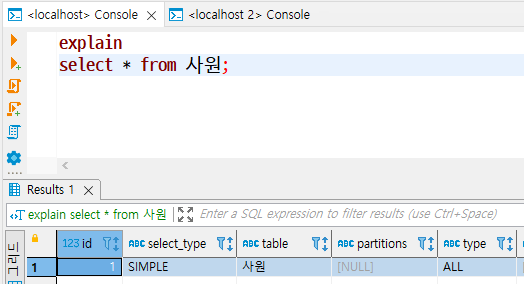
ALL
- 테이블을 처음부터 끝까지 읽는 테이블 풀 스캔 방식에 해당되는 유형
- 활용할 수 있는 인덱스가 없거나, 인덱스를 활용하는게 오히려 비효율적이라고 옵티마이저가 판단했을 때 선택된다.
- ALL 유형일 때는 인덱스를 새로 추가하거나 기존 인덱스를 변경하여 인덱스를 활용하는 방식으로 SQL 튜닝을 할 수 있지만, 전체 테이블 중 10~20% 이상 분량의 데이터를 조회할 때는 ALL 유형의 성능이 오히려 유리할 수 있다.
6. possible_key
- 옵티마이저가 SQL 문을 최적화하기 위해 사용할 수 있는 인덱스 목록을 출력한다.
- 실제 사용한 인덱스가 아닌, 사용할 수 있는 후보군의 기본 키와 인덱스 목록만 보여주므로 SQL 튜닝의 효용성은 없다.
7. key
- 옵티마이저가 SQL 문을 최적화하기 위해 사용한 기본 키 또는 인덱스명을 의미한다.
- 어느 인덱스로 데이터를 검색했는지 확인할 수 있으므로, 비효율적인 인덱스를 사용했거나 인덱스 자체를 사용하지 않았다면 SQL 튜닝의 대상이 된다.
- key 값이 NULL인 경우, 기본 키와 인덱스를 전혀 사용하지 않았다는 것을 의미한다.
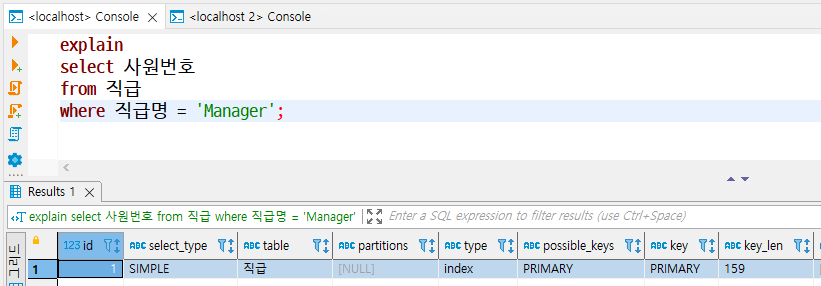
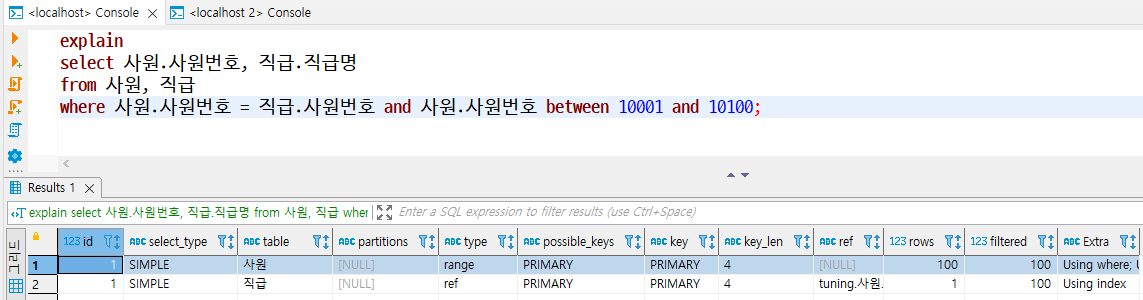
8. key_len
- 인덱스를 사용할 때는 인덱스 전체를 사용하거나 일부 인덱스만 사용하는데, key_len은 사용한 인덱스의 바이트 수를 의미한다.
- UTF-8 기준으로 INT 데이터 유형은 단위당 4바이트, VARCHAR 데이터 유형은 단위당 3바이트이다.
- 위 예제에서 직급 테이블은 데이터에 접근할 때 사원번호와 직급명, 시작일자 열을 결합한 기본키를 사용하는데, 사원번호는 INT로 4바이트, 직급명은 varchar(50)으로 (50 + 1) * 3바이트 = 155바이트에 해당한다.
- 즉, PK에서 사원번호의 4바이트와 직급명의 155바이트만 사용해서 key_len이 159바이트로 출력된다.
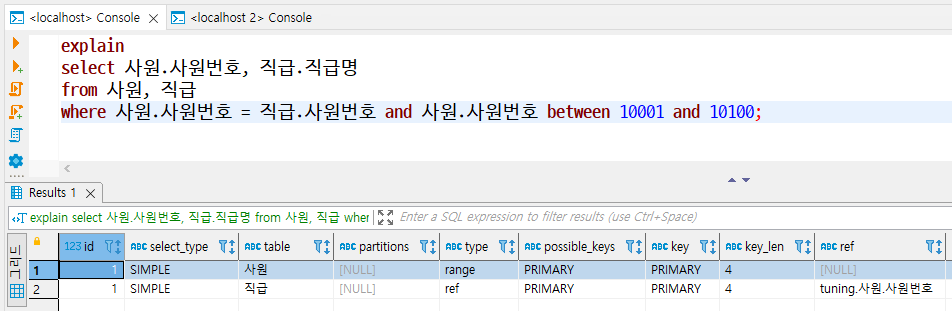
9. ref
- 테이블 조인을 수행할 때 어떤 조건으로 해당 테이블에 액세스되었는지를 알려준다.
10. rows
- SQL 문을 수행하고자 접근하는 데이터의 모든 행 수를 나타내는 예측 항목
- 디스크에서 데이터 파일을 읽고 메모리에서 처리해야 할 행 수를 예상하는 값으로, 수시로 변동되는 MySQL 통계 정보를 참고하여 산출하는 값이므로 정확하지 않다.
- SQL 문의 최종 결과 건수와 비교해 rows 수가 크게 차이날 때는 불필요하게 MySQL 엔진에 데이터를 많이 가져왔다는 뜻이므로 SQL 튜닝 대상이 될 수 있다.
11. filtered
- SQL 문을 통해 DB 엔진으로 가져온 데이터 대상으로 필터 조건에 따라 어느 정도의 비율로 데이터를 제거했는지를 의미하는 항목
- 만약 100건에서 10건으로 필터링된 경우 filtered 값은 10이 된다. (단위는 %)
12. extra
- SQL 문을 어떻게 수행할 것인지에 관한 추가 정보를 보여주는 항목으로, 세미콜론으로 구분하여 여러 가지 정보를 나열할 수 있다.
Distinct
- 중복이 제거되어 유일한 값을 찾을 때 출력되는 정보
- 중복 제거가 포함되는 distinct 키워드나 union 구문이 포함된 경우 출력된다.
Using where
- WHERE 절의 필터 조건을 사용해 MySQL 엔진으로 가져온 데이터를 추출할 것이라는 의미
Using temporary
- 데이터의 중간 결과를 저장하고자 임시 테이블을 생성하겠다는 의미로, 데이터를 가져와 저장한 뒤에 정렬 작업을 수행하거나 중복을 제거하는 작업 등을 수행한다.
- 보통 DISTINCT, GROUP BY, ORDER BY 구문이 포함된 경우 출력된다.
- 임시 테이블을 메모리에 생성하거나, 메모리 영역을 초과하여 디스크에 임시 테이블을 생성하면 성능 저하의 원인이 되므로, Using temporary가 출력되는 쿼리는 SQL 튜닝 대상이 될 수 있다.
Using index
- 물리적인 데이터 파일을 읽지 않고 인덱스만 읽어서 SQL 문의 요청사항을 처리할 수 있는 경우를 의미
- 커버링 인덱스 방식이라고 부르며, 인덱스로 구성된 열만 SQL 문에서 사용할 경우 이 방식을 활용한다.
- 물리적으로도 테이블보다 인덱스가 작고 정렬되어 있으므로 적은 양의 데이터에 접근할 때 성능 측면에서 효율적이다.

추가 정보
- EXPLAIN이 제공하는 정보 외에도 확장된 실행 계획 명령어를 통해 추가 정보를 얻을 수 있다.
- MySQL과 MariaDB에서 제공하는 명령어는 다음과 같다.
MySQL
EXPLAIN FORMAT = TRADITIONAL
- 기본적인 실행 계획은 EXPLAIN 키워드를 사용하며, 기본 포맷은 TRADITIONAL
- 따라서, 명시하지 않는 경우 기본적인 실행 계획 정보가 출력된다.
EXPLAIN FORMAT = TRADITIONAL
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 100001 AND 200000;
EXPLAIN FORMAT = TREE
- 형식값에 TREE 옵션을 입력하면 트리 형태로 추가된 실행 계획 항목을 확인할 수 있다.

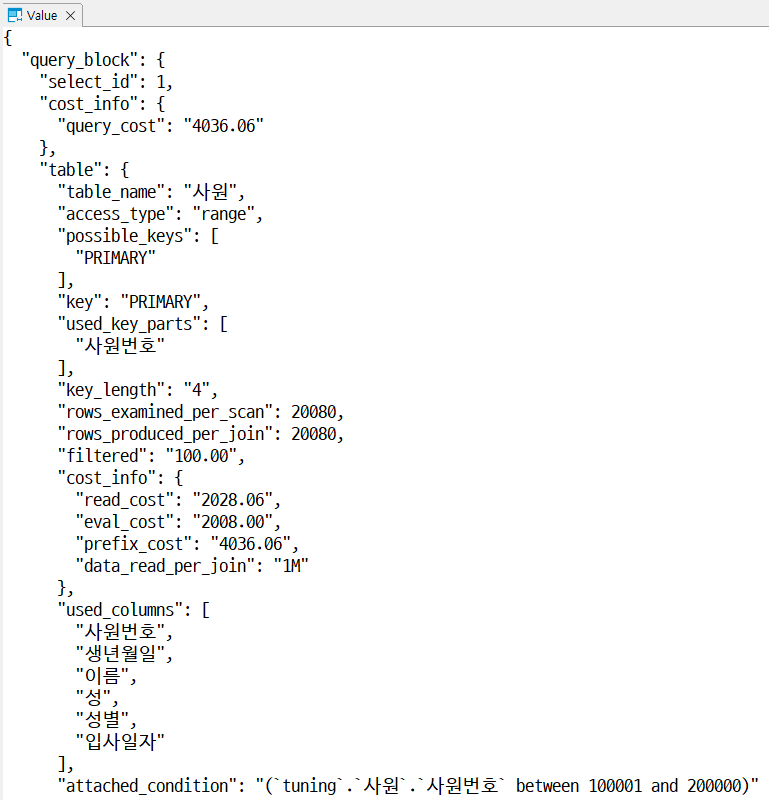
EXPLAIN FORMAT = JSON
- 형식값에 JSON 옵션을 입력하면 JSON 형태로 추가된 실행 계획 항목을 확인할 수 있다.
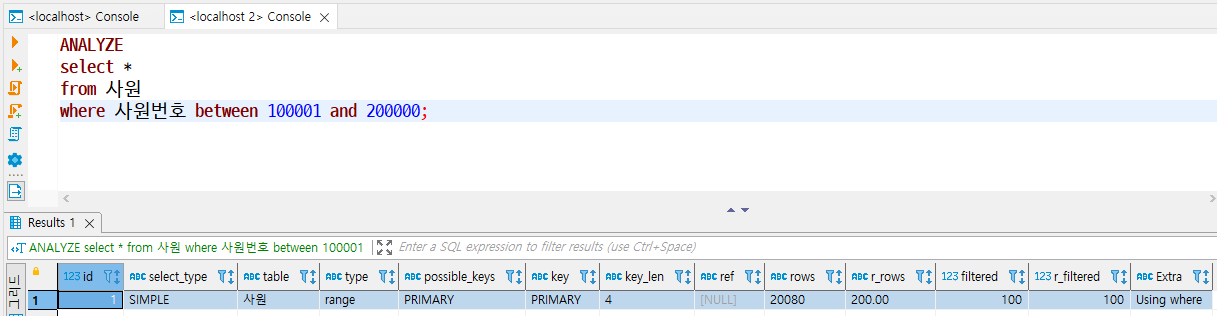
EXPLAIN ANALYZE
- 이전까지 사용한 실행 계획은 예측된 실행 계획에 관한 정보로, 만약 실제 측정한 실행 계획 정보를 출력하고 싶다면 ANALYZE 키워드를 사용한다.
- 실제 수행된 소요 시간과 비용을 측정하여 실측 실행 계획과 예측 실행 계획 모두를 확인할 수 있다.

MariaDB
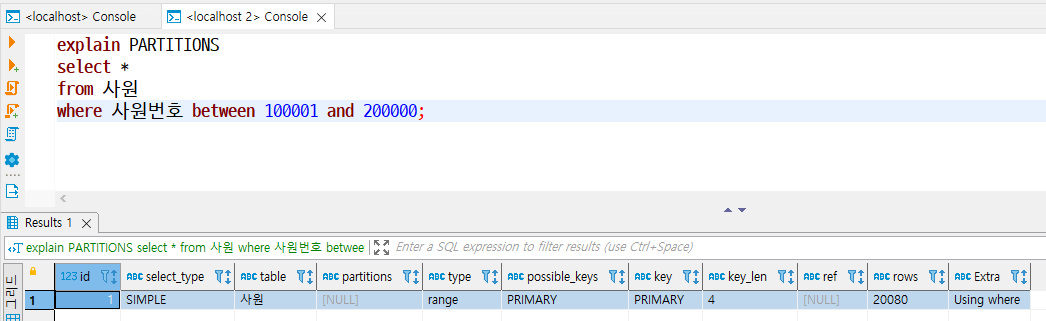
EXPLAIN PARTITONS
- 파티션으로 설정된 테이블에 대해 접근 대상인 파티션 정보를 출력한다.
EXPLAIN EXTENDED
- 스토리지 엔진에서 가져온 데이터를 다시 MySQL 엔진에서 추출한 비율인 filtered 열의 값을 추가로 출력한다.

ANALYZE
- MariaDB 10.1 이상부터 사용할 수 있으며, 실제 측정한 실행 계획 정보가 출력된다.
- 실제 액세스한 데이터 건수(r_rows)와 MySQL 엔진에서 가져온 데이터에서 추가로 추출한 데이터의 비율(r_filtered)을 확인할 수 있다.